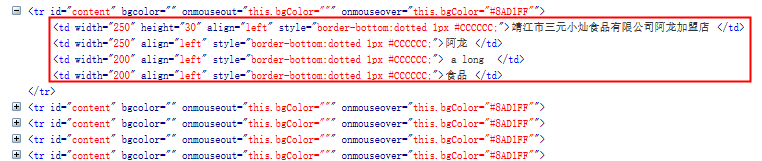
.NET中识别文件编码、识别字符集,有一个比较好用的包UDE.CSharp可以实现,这个包是Mozilla出品的,又叫Mozilla Universal Charset Detector。
首先在nuget下载安装UED:
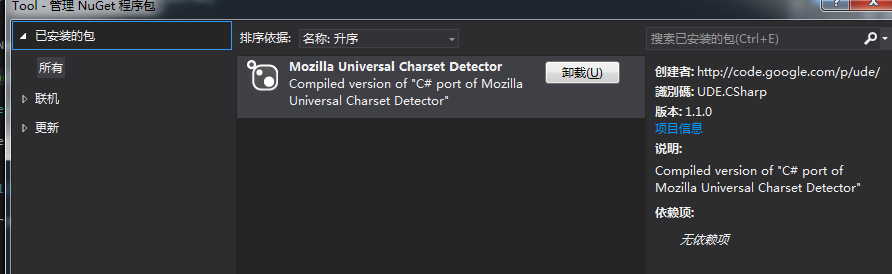

使用样例如下:
private void btnImport_Click(object sender, EventArgs e)
{
OpenFileDialog dlg = new OpenFileDialog();
dlg.DefaultExt = ".txt";
dlg.Filter = "txt文件|*.txt";
if (dlg.ShowDialog() == System.Windows.Forms. DialogResult.OK)
{
_list.Clear();
string filename = dlg.FileName;
//使用Mozilla Universal Charset Detector侦测文件编码
string charset = "UTF-8";
using ( FileStream fs = File .OpenRead(filename))
{
Ude. CharsetDetector cdet = new Ude.CharsetDetector ();
cdet.Feed(fs);
cdet.DataEnd();
if (cdet.Charset != null)
{
charset = cdet.Charset;
}
}
string[] lines = File.ReadAllLines(filename, Encoding.GetEncoding(charset));
foreach ( var line in lines)
{
//去重
if (_list.IndexOf(line) == -1)
{
_list.Add(line);
}
}
}
}